 In the Parse and Enter phase, the compiler parses source files into an Abstract Syntax Tree (AST). Think of the AST as the DOM-equivalent for Java code. Parsing will only throw errors if the syntax is invalid. Compilation errors such as invalid class or method usage are checked in phase 3.
In the Annotation Processing phase, custom annotation processors are invoked. This is considered a pre-compilation phase. Annotation processors can do things like validate classes or generate new resources, including source files. Annotation processors can generate errors that will cause the compilation process to fail. If new source files are generated as a result of annotation processing, then compilation loops back to the Parse and Enter phase and the process is repeated until no new source files are generated.
In the last phase, Analyse and Generate, the compiler generates class files (byte code) from the Abstract Syntax Trees generated in phase 1. As part of this process, the AST is analyzed for broken references (e.g. class not found, method not found), valid flow is checked (e.g. no unreachable statements), type erasure is performed, syntactic sugar is desugared (e.g. enhanced for loops become iterator loops) and finally, if everything is successful, class files are written out.
Project Lombok and Compilation
Project Lombok hooks itself into the compilation process as an annotation processor. But Lombok is not your normal annotation processor. Normally, annotation processors only generate new source files whereas Lombok modifies existing classes.
The trick is that Lombok modifies the AST. It turns out that changes made to the AST in the Annotation Processing phase will be visible to the Analyse and Generate phase. Thus, changing the AST will change the generated class file. For example, if a method node is added to the AST, then the class file will contain that new method. By modifying the AST, Lombok can do things like generate new methods (getter, setter, equals, etc) or inject code into an existing method (e.g. cleaning up resources).
Trick or Hack?
Some people call Lombok's trick a hack, and I'd agree. But don't pass judgement yet. Like any hack, you should examine the risk/reward and alternatives before determining if you are comfortable with it.
The "hack" in Lombok is that, strictly speaking, the annotation processing spec doesn't allow you to modify existing classes. The annotation processing API doesn't provide a mechanism for changing the AST of a class. The clever people at Project Lombok got around this through some unpublished APIs of javac. Since Eclipse uses an internal compiler, Lombok also needs access to internal APIs of the Eclipse compiler.
If Java officially supported compile-time AST transformations then Lombok wouldn't need to rely on backdoor APIs. This makes Project Lombok vulnerable to future changes in the JDK. There is no guarantee the private APIs won't change in a later JDK and break Project Lombok. If that happens, then you're left hoping that the guys at Lombok will be responsive about patching their library to work with the new JDK. Same thing goes for the new Eclipse compilers. Given how often we get a new version of Java, this may not be that big of an issue.
Alternatives in Java
There are other alternatives for modifying the behavior of classes. One approach is to use byte-code manipulation at runtime via a library like CGLib or ASM. This is how Hibernate is able to do things like lazily initialize a persistent Collection the first time it is accessed. In general, this can be used to enhance the behavior of existing methods. This trick could possibly be used to implement the @Cleanup behavior in Lombok, so that a resource is closed when it goes out of scope. Runtime byte-code manipulation is no help for generating getters and setters which you intend to reference in source code.
Another approach is to use byte-code manipulation on the class files. For example, Kohsuke Kawaguchi of Hudson fame created a library called Bridge Method Injector, that helps perserve binary compatibility when changing a method's return type in a way that is source compatible but not binary compatible. Kohsuke implements this by using ASM to modify the byte-code in a class file after compilation. This trick could be used to mimic the behavior of the Getter/Setter/ToString/EqualsHashCode annotations of Lombok with one caveat: generated methods would only be visible to classes external to your library but not to classes within your library. In other words, projects that depended on classes in your library as a jar would see your getters and setters, but classes within your library would not see these getters and setters at compile time.
The trick that makes Lombok special is that the code it generates is weaved in before Analyze and Generate phase of compilation. This allows classes within the same compilation unit to have visibility to the generated methods. It appears another library called Juast may be using a similar trick (modifying the AST) to do things like operator overloading. For some developers, the immediate benefits of Lombok's approach may outweigh the potential risks.
Alternatives outside Java
If you're willing to switch to Scala, Lombok becomes a moot point. Scala has Case classes that eliminate the getter/setter/toString/hashCode/equals boiler-plate. Scala also has Automatic Resource Management that covers Lombok's @Cleanup behavior.
Another option is Groovy if you don't care about static typing. Groovy has similar support for Scala-like Case classes. Groovy also officially supports compile-time, AST transformations.
Final thoughts
Project Lombok can do tricks that are impossible via other dynamic code generation methods in Java but you should be aware the it uses some back-door APIs to accomplish it.
In the Parse and Enter phase, the compiler parses source files into an Abstract Syntax Tree (AST). Think of the AST as the DOM-equivalent for Java code. Parsing will only throw errors if the syntax is invalid. Compilation errors such as invalid class or method usage are checked in phase 3.
In the Annotation Processing phase, custom annotation processors are invoked. This is considered a pre-compilation phase. Annotation processors can do things like validate classes or generate new resources, including source files. Annotation processors can generate errors that will cause the compilation process to fail. If new source files are generated as a result of annotation processing, then compilation loops back to the Parse and Enter phase and the process is repeated until no new source files are generated.
In the last phase, Analyse and Generate, the compiler generates class files (byte code) from the Abstract Syntax Trees generated in phase 1. As part of this process, the AST is analyzed for broken references (e.g. class not found, method not found), valid flow is checked (e.g. no unreachable statements), type erasure is performed, syntactic sugar is desugared (e.g. enhanced for loops become iterator loops) and finally, if everything is successful, class files are written out.
Project Lombok and Compilation
Project Lombok hooks itself into the compilation process as an annotation processor. But Lombok is not your normal annotation processor. Normally, annotation processors only generate new source files whereas Lombok modifies existing classes.
The trick is that Lombok modifies the AST. It turns out that changes made to the AST in the Annotation Processing phase will be visible to the Analyse and Generate phase. Thus, changing the AST will change the generated class file. For example, if a method node is added to the AST, then the class file will contain that new method. By modifying the AST, Lombok can do things like generate new methods (getter, setter, equals, etc) or inject code into an existing method (e.g. cleaning up resources).
Trick or Hack?
Some people call Lombok's trick a hack, and I'd agree. But don't pass judgement yet. Like any hack, you should examine the risk/reward and alternatives before determining if you are comfortable with it.
The "hack" in Lombok is that, strictly speaking, the annotation processing spec doesn't allow you to modify existing classes. The annotation processing API doesn't provide a mechanism for changing the AST of a class. The clever people at Project Lombok got around this through some unpublished APIs of javac. Since Eclipse uses an internal compiler, Lombok also needs access to internal APIs of the Eclipse compiler.
If Java officially supported compile-time AST transformations then Lombok wouldn't need to rely on backdoor APIs. This makes Project Lombok vulnerable to future changes in the JDK. There is no guarantee the private APIs won't change in a later JDK and break Project Lombok. If that happens, then you're left hoping that the guys at Lombok will be responsive about patching their library to work with the new JDK. Same thing goes for the new Eclipse compilers. Given how often we get a new version of Java, this may not be that big of an issue.
Alternatives in Java
There are other alternatives for modifying the behavior of classes. One approach is to use byte-code manipulation at runtime via a library like CGLib or ASM. This is how Hibernate is able to do things like lazily initialize a persistent Collection the first time it is accessed. In general, this can be used to enhance the behavior of existing methods. This trick could possibly be used to implement the @Cleanup behavior in Lombok, so that a resource is closed when it goes out of scope. Runtime byte-code manipulation is no help for generating getters and setters which you intend to reference in source code.
Another approach is to use byte-code manipulation on the class files. For example, Kohsuke Kawaguchi of Hudson fame created a library called Bridge Method Injector, that helps perserve binary compatibility when changing a method's return type in a way that is source compatible but not binary compatible. Kohsuke implements this by using ASM to modify the byte-code in a class file after compilation. This trick could be used to mimic the behavior of the Getter/Setter/ToString/EqualsHashCode annotations of Lombok with one caveat: generated methods would only be visible to classes external to your library but not to classes within your library. In other words, projects that depended on classes in your library as a jar would see your getters and setters, but classes within your library would not see these getters and setters at compile time.
The trick that makes Lombok special is that the code it generates is weaved in before Analyze and Generate phase of compilation. This allows classes within the same compilation unit to have visibility to the generated methods. It appears another library called Juast may be using a similar trick (modifying the AST) to do things like operator overloading. For some developers, the immediate benefits of Lombok's approach may outweigh the potential risks.
Alternatives outside Java
If you're willing to switch to Scala, Lombok becomes a moot point. Scala has Case classes that eliminate the getter/setter/toString/hashCode/equals boiler-plate. Scala also has Automatic Resource Management that covers Lombok's @Cleanup behavior.
Another option is Groovy if you don't care about static typing. Groovy has similar support for Scala-like Case classes. Groovy also officially supports compile-time, AST transformations.
Final thoughts
Project Lombok can do tricks that are impossible via other dynamic code generation methods in Java but you should be aware the it uses some back-door APIs to accomplish it.
Friday, November 26, 2010
Project Lombok - Trick Explained
In my previous blog post, I introduced Project Lombok, a library that can inject code into a class at compile time. When you see it in action, it almost seems magical. I will attempt to explain the trick behind the magic.
Java Compilation
To understand how Project Lombok works, one must first understand how Java compilation works. OpenJDK provides an excellent overview of the compilation process. To paraphrase, compilation has 3 stages:
1. Parse and Enter
2. Annotation Processing
3. Analyse and Generate
In the Parse and Enter phase, the compiler parses source files into an Abstract Syntax Tree (AST). Think of the AST as the DOM-equivalent for Java code. Parsing will only throw errors if the syntax is invalid. Compilation errors such as invalid class or method usage are checked in phase 3.
In the Annotation Processing phase, custom annotation processors are invoked. This is considered a pre-compilation phase. Annotation processors can do things like validate classes or generate new resources, including source files. Annotation processors can generate errors that will cause the compilation process to fail. If new source files are generated as a result of annotation processing, then compilation loops back to the Parse and Enter phase and the process is repeated until no new source files are generated.
In the last phase, Analyse and Generate, the compiler generates class files (byte code) from the Abstract Syntax Trees generated in phase 1. As part of this process, the AST is analyzed for broken references (e.g. class not found, method not found), valid flow is checked (e.g. no unreachable statements), type erasure is performed, syntactic sugar is desugared (e.g. enhanced for loops become iterator loops) and finally, if everything is successful, class files are written out.
Project Lombok and Compilation
Project Lombok hooks itself into the compilation process as an annotation processor. But Lombok is not your normal annotation processor. Normally, annotation processors only generate new source files whereas Lombok modifies existing classes.
The trick is that Lombok modifies the AST. It turns out that changes made to the AST in the Annotation Processing phase will be visible to the Analyse and Generate phase. Thus, changing the AST will change the generated class file. For example, if a method node is added to the AST, then the class file will contain that new method. By modifying the AST, Lombok can do things like generate new methods (getter, setter, equals, etc) or inject code into an existing method (e.g. cleaning up resources).
Trick or Hack?
Some people call Lombok's trick a hack, and I'd agree. But don't pass judgement yet. Like any hack, you should examine the risk/reward and alternatives before determining if you are comfortable with it.
The "hack" in Lombok is that, strictly speaking, the annotation processing spec doesn't allow you to modify existing classes. The annotation processing API doesn't provide a mechanism for changing the AST of a class. The clever people at Project Lombok got around this through some unpublished APIs of javac. Since Eclipse uses an internal compiler, Lombok also needs access to internal APIs of the Eclipse compiler.
If Java officially supported compile-time AST transformations then Lombok wouldn't need to rely on backdoor APIs. This makes Project Lombok vulnerable to future changes in the JDK. There is no guarantee the private APIs won't change in a later JDK and break Project Lombok. If that happens, then you're left hoping that the guys at Lombok will be responsive about patching their library to work with the new JDK. Same thing goes for the new Eclipse compilers. Given how often we get a new version of Java, this may not be that big of an issue.
Alternatives in Java
There are other alternatives for modifying the behavior of classes. One approach is to use byte-code manipulation at runtime via a library like CGLib or ASM. This is how Hibernate is able to do things like lazily initialize a persistent Collection the first time it is accessed. In general, this can be used to enhance the behavior of existing methods. This trick could possibly be used to implement the @Cleanup behavior in Lombok, so that a resource is closed when it goes out of scope. Runtime byte-code manipulation is no help for generating getters and setters which you intend to reference in source code.
Another approach is to use byte-code manipulation on the class files. For example, Kohsuke Kawaguchi of Hudson fame created a library called Bridge Method Injector, that helps perserve binary compatibility when changing a method's return type in a way that is source compatible but not binary compatible. Kohsuke implements this by using ASM to modify the byte-code in a class file after compilation. This trick could be used to mimic the behavior of the Getter/Setter/ToString/EqualsHashCode annotations of Lombok with one caveat: generated methods would only be visible to classes external to your library but not to classes within your library. In other words, projects that depended on classes in your library as a jar would see your getters and setters, but classes within your library would not see these getters and setters at compile time.
The trick that makes Lombok special is that the code it generates is weaved in before Analyze and Generate phase of compilation. This allows classes within the same compilation unit to have visibility to the generated methods. It appears another library called Juast may be using a similar trick (modifying the AST) to do things like operator overloading. For some developers, the immediate benefits of Lombok's approach may outweigh the potential risks.
Alternatives outside Java
If you're willing to switch to Scala, Lombok becomes a moot point. Scala has Case classes that eliminate the getter/setter/toString/hashCode/equals boiler-plate. Scala also has Automatic Resource Management that covers Lombok's @Cleanup behavior.
Another option is Groovy if you don't care about static typing. Groovy has similar support for Scala-like Case classes. Groovy also officially supports compile-time, AST transformations.
Final thoughts
Project Lombok can do tricks that are impossible via other dynamic code generation methods in Java but you should be aware the it uses some back-door APIs to accomplish it.
In the Parse and Enter phase, the compiler parses source files into an Abstract Syntax Tree (AST). Think of the AST as the DOM-equivalent for Java code. Parsing will only throw errors if the syntax is invalid. Compilation errors such as invalid class or method usage are checked in phase 3.
In the Annotation Processing phase, custom annotation processors are invoked. This is considered a pre-compilation phase. Annotation processors can do things like validate classes or generate new resources, including source files. Annotation processors can generate errors that will cause the compilation process to fail. If new source files are generated as a result of annotation processing, then compilation loops back to the Parse and Enter phase and the process is repeated until no new source files are generated.
In the last phase, Analyse and Generate, the compiler generates class files (byte code) from the Abstract Syntax Trees generated in phase 1. As part of this process, the AST is analyzed for broken references (e.g. class not found, method not found), valid flow is checked (e.g. no unreachable statements), type erasure is performed, syntactic sugar is desugared (e.g. enhanced for loops become iterator loops) and finally, if everything is successful, class files are written out.
Project Lombok and Compilation
Project Lombok hooks itself into the compilation process as an annotation processor. But Lombok is not your normal annotation processor. Normally, annotation processors only generate new source files whereas Lombok modifies existing classes.
The trick is that Lombok modifies the AST. It turns out that changes made to the AST in the Annotation Processing phase will be visible to the Analyse and Generate phase. Thus, changing the AST will change the generated class file. For example, if a method node is added to the AST, then the class file will contain that new method. By modifying the AST, Lombok can do things like generate new methods (getter, setter, equals, etc) or inject code into an existing method (e.g. cleaning up resources).
Trick or Hack?
Some people call Lombok's trick a hack, and I'd agree. But don't pass judgement yet. Like any hack, you should examine the risk/reward and alternatives before determining if you are comfortable with it.
The "hack" in Lombok is that, strictly speaking, the annotation processing spec doesn't allow you to modify existing classes. The annotation processing API doesn't provide a mechanism for changing the AST of a class. The clever people at Project Lombok got around this through some unpublished APIs of javac. Since Eclipse uses an internal compiler, Lombok also needs access to internal APIs of the Eclipse compiler.
If Java officially supported compile-time AST transformations then Lombok wouldn't need to rely on backdoor APIs. This makes Project Lombok vulnerable to future changes in the JDK. There is no guarantee the private APIs won't change in a later JDK and break Project Lombok. If that happens, then you're left hoping that the guys at Lombok will be responsive about patching their library to work with the new JDK. Same thing goes for the new Eclipse compilers. Given how often we get a new version of Java, this may not be that big of an issue.
Alternatives in Java
There are other alternatives for modifying the behavior of classes. One approach is to use byte-code manipulation at runtime via a library like CGLib or ASM. This is how Hibernate is able to do things like lazily initialize a persistent Collection the first time it is accessed. In general, this can be used to enhance the behavior of existing methods. This trick could possibly be used to implement the @Cleanup behavior in Lombok, so that a resource is closed when it goes out of scope. Runtime byte-code manipulation is no help for generating getters and setters which you intend to reference in source code.
Another approach is to use byte-code manipulation on the class files. For example, Kohsuke Kawaguchi of Hudson fame created a library called Bridge Method Injector, that helps perserve binary compatibility when changing a method's return type in a way that is source compatible but not binary compatible. Kohsuke implements this by using ASM to modify the byte-code in a class file after compilation. This trick could be used to mimic the behavior of the Getter/Setter/ToString/EqualsHashCode annotations of Lombok with one caveat: generated methods would only be visible to classes external to your library but not to classes within your library. In other words, projects that depended on classes in your library as a jar would see your getters and setters, but classes within your library would not see these getters and setters at compile time.
The trick that makes Lombok special is that the code it generates is weaved in before Analyze and Generate phase of compilation. This allows classes within the same compilation unit to have visibility to the generated methods. It appears another library called Juast may be using a similar trick (modifying the AST) to do things like operator overloading. For some developers, the immediate benefits of Lombok's approach may outweigh the potential risks.
Alternatives outside Java
If you're willing to switch to Scala, Lombok becomes a moot point. Scala has Case classes that eliminate the getter/setter/toString/hashCode/equals boiler-plate. Scala also has Automatic Resource Management that covers Lombok's @Cleanup behavior.
Another option is Groovy if you don't care about static typing. Groovy has similar support for Scala-like Case classes. Groovy also officially supports compile-time, AST transformations.
Final thoughts
Project Lombok can do tricks that are impossible via other dynamic code generation methods in Java but you should be aware the it uses some back-door APIs to accomplish it.
Thursday, November 11, 2010
Project Lombok: Annotation-driven development - Part 1
As the Java language has reached an evolutionary plateau, annotations are emerging as a way to extend the language. Two interesting frameworks that I've been looking at are Project Lombok and the Checker Framework. In this first entry of a series I'm calling "Annotation-driven development", I'll be looking at Project Lombok.
Project Lombok
Project Lombok aims to eliminate boilerplate code. For example most POJO classes are littered with trivial getters/setters like the following:
public class Person {
private final String firstName; // read-only
private String lastName;
public Person(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
public String getFirstName() {
return firstName;
}
public String getLastName() {
return lastName;
}
public void setLastName(String value) {
this.lastName = value;
}
}
With Lombok, you can use annotations to create the equivalent set of methods:
@AllArgsConstructor
public class Person {
@Getter @Setter private final String firstName;
@Getter private String lastName;
}
Or even simpler:
@Data
public class Person {
private final String firstName;
private String lastName;
}
Actually, the final example generates more than just getters/setters and constructor. You also get a toString and hashCode method, which are often "forgotten" because they are a pain to write correctly (unless you are using Pojomatic).
Lombok isn't just about POJO boilerplate. From the Project Lombok features page, here are all the annotations available currently:
@Getter/@SetterNever writepublic int getFoo() {return foo;}again.<@ToStringNo need to start a debugger to see your fields: Just let lombok generate atoStringfor you!@EqualsAndHashCodeEquality made easy: GenerateshashCodeandequalsimplementations from the fields of your object.@NoArgsConstructor,@RequiredArgsConstructorand@AllArgsConstructorConstructors made to order: Generates constructors that take no arguments, one argument per final / non-null field, or one argument for every field.@DataAll together now: A shortcut for@ToString,@EqualsAndHashCode,@Getteron all fields, and@Setteron all non-final fields, and@RequiredArgsConstructor!@CleanupAutomatic resource management: Call yourclose()methods safely with no hassle.@Synchronizedsynchronizeddone right: Don't expose your locks.@SneakyThrowsTo boldly throw checked exceptions where no one has thrown them before!
Setting up Lombok
To use lombok, you'll need the lombok.jar. This can be obtained from the Project Lombok website. Maven users can simply add the lombok dependency and repository. For example:
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>0.9.3</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>projectlombok.org</id>
<url>http://projectlombok.org/mavenrepo</url>
</repository>
</repositories>
</repositories>
This will allow you to use lombok using javac.
For the 99.9% of developers who use an IDE, you'll want Lombok IDE support unless you enjoy seeing code that won't compile. You're in luck if you're using Eclipse or NetBeans, as those are the only IDEs supported (sorry IntelliJ users).
For Eclipse 3+ and NetBeans 6.8+, simply run java -jar lombok.jar and an install wizard will guide you through adding Lombok support to your chosen IDE(s). The wizard will modify your IDE start script to include Lombok.jar as a Java agent. NetBeans 6.9 users also have the option of using Lombok as a inline annotation processor.
Using Lombok
Once you're got your environment set up to use Lombok, you simply add a Lombok annotation your class, and your class is magically enhanced. Lombok generates code during the compilation phase. Within the IDE, you'll now have access to methods that aren't in your source file. The methods exist in the generated class so they show up in your class outline and are available for code completion. If you ask your IDE to open/jump to the method, it will open the source file but obviously you won't see the code for the method. If you want to view the generated code, you can use JAD to decompile the class or you can use the delombok tool to generate a Lomboked source file from your original source file. You can run delombok manually from the command-line or automatically via the Maven Lombok plugin. Despite being a Maven user, I found it easier to use delombok from the command-line because the maven plugin requires moving all Lomboked files to a non-standard directory. Delombok serves a few useful purposes. You may be curious to see what code Lombok is generating. Or you later decide you want to remove your dependency on Lombok, then you can delombok all your source, and replace the original source with the delomboked source. Running Delombok on the previously mentioned @Data example, generated the following source code:
public class Person {
private final String firstName;
private String lastName;
@java.beans.ConstructorProperties({"firstName"})
@java.lang.SuppressWarnings("all")
public Person(final String firstName) {
this.firstName = firstName;
}
@java.lang.SuppressWarnings("all")
public String getFirstName() {
return this.firstName;
}
@java.lang.SuppressWarnings("all")
public String getLastName() {
return this.lastName;
}
@java.lang.SuppressWarnings("all")
public void setLastName(final String lastName) {
this.lastName = lastName;
}
@java.lang.Override
@java.lang.SuppressWarnings("all")
public boolean equals(final java.lang.Object o) {
if (o == this) return true;
if (o == null) return false;
if (o.getClass() != this.getClass()) return false;
final Person other = (Person)o;
if (this.getFirstName() == null ? other.getFirstName() != null : !this.getFirstName().equals(other.getFirstName())) return false;
if (this.getLastName() == null ? other.getLastName() != null : !this.getLastName().equals(other.getLastName())) return false;
return true;
}
@java.lang.Override
@java.lang.SuppressWarnings("all")
public int hashCode() {
final int PRIME = 31;
int result = 1;
result = result * PRIME + (this.getFirstName() == null ? 0 : this.getFirstName().hashCode());
result = result * PRIME + (this.getLastName() == null ? 0 : this.getLastName().hashCode());
return result;
}
@java.lang.Override
@java.lang.SuppressWarnings("all")
public java.lang.String toString() {
return "Person(firstName=" + this.getFirstName() + ", lastName=" + this.getLastName() + ")";
}
}
Like any source code generator, delombok produces code that looks, well, generated. It seems that Lombok lazily adds @java.lang.SuppressWarnings("all") to all methods. The toString/hasCode/equals methods are definitely uglier that what you'd get if you were using Pojomatic.
Extending Lombok
After playing with Lombok, you will likely think of other boilerplate code you'd like to eliminate using the Lombok. The Builder pattern came to my mind and apparently others others as well. There are very few resources that explain how to extend Lombok. You can obviously download the source. Besides that, the best resource I could find was a blog by Nicolas Frankel that describes the basic steps as well as example source. Nicolas states that writing custom Lombok plugins is not for the faint-hearted and I'd agree. You'll quickly discover that you need to know something about annotation processors as well as some rather low-level Javac APIs. Honestly, when you look under the covers of Lombok, things get a bit scary. Some have called Lombok a hack because it relies on internal javac APIs.Final Thoughts
Lombok is a very interesting use of annotations to extend the Java language. For those who really hate writing getters/setters/etc, Lombok is worth checking out. Although I don't enjoy writing getters/setters/etc, I don't spend a lot of my time writing those types of methods and the IDE can generate much of the boilerplate. It should be noted that Scala has eliminated many of the pain points that Lombok aims to remedy. Right now I'm just using Lombok for prototyping. It definitely speeds up the process of creating POJOs and let's me focus on the more interesting aspects of the prototype. I am not using Lombok for production code. Although I use Eclipse, other developers at Overstock use IntelliJ and the lack of support for IntelliJ is a show-stopper. Even if all IDEs were supported, I'm still not comfortable unleashing Lombok until I've spent some more time with it. I don't think I've found all its warts yet. I'm also concerned about later releases of JDK (or Eclipse) breaking Lombok compatibility. It wouldn't be the end of the world because I can always delombok my source, but that could be a painful process for large projects. That said, it's definitely worth looking Lombok. Even if it never makes it into my Java toolkit, it's a fascinating library to examine and my knowledge of Java has increased because of it.Wednesday, October 27, 2010
Passing properties to the Maven release plugin
The Maven release plugin does not propagate system properties to the maven release build. This can cause confusion when you try to set properties for a maven release. For example, if your pom.xml uses a custom property "some-property" that you intend to set for a release, you might be tempted to try this:
Although this works for regular build, it will not work for a release build. This is because the release plugin forks a new instance for the release build, and properties passed to the parent are not propagated to the forked build.
To solve this problem, you need to propagate the properties yourself by configuring the argument property of the release plugin. For example:
If you need to propagate more than 1 property, the arguments property allows for multiple values separated by spaces.
mvn release:prepare -Dsome-property=foo
Although this works for regular build, it will not work for a release build. This is because the release plugin forks a new instance for the release build, and properties passed to the parent are not propagated to the forked build.
To solve this problem, you need to propagate the properties yourself by configuring the argument property of the release plugin. For example:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.overstock.example</groupId>
<artifactId>helloworld</artifactId>
<packaging>jar</packaging>
<version>1.0-SNAPSHOT</version>
<name>helloworld</name>
<url>http://maven.apache.org</url>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-release-plugin</artifactId>
<configuration>
<arguments>-Dsome-property=${some-property}</arguments>
</configuration>
</plugin>
</plugins>
</build>
</project>
If you need to propagate more than 1 property, the arguments property allows for multiple values separated by spaces.
Monday, October 4, 2010
Custom Hudson Plugins
Where to Begin
So you want to write a Hudson plugin but don't know where to start. Luckily, it's fairly easy to get started by following the tutorial on the official Hudson wiki: http://wiki.hudson-ci.org/display/HUDSON/Plugin+tutorial. If all you need is a simple Hudson builder, the Hudson tutorial should suffice. The purpose of this blog post is to supplement that tutorial with additional hints and explanations to make your journey a bit easier.
After following the Hudson plugin tutorial you should end up with a fully-functioning HelloWorld Hudson plugin that can be run from the command-line by running mvn clean hpi:run. Running clean is optional, but I highly recommend cleaning because I have had many moments where my plugin wasn't working as expected, only to discover after much troubleshooting that I didn't clean. If everything works, you should be able to connect to your custom Hudson instance via localhost:8080.
Testing the HelloWorld Builder plugin
Once you've got Hudson running, you're ready to configure the HelloWorld Builder plugin. Hudson provides 2-levels of configuration, global and job. To access, global configuration navigate to Hudson->Manage Hudson->Configure System. Here you will find a section labeled "Hello World Builder" with a configuration checkbox for French. This controls the default language of the plugin.
Now it's time to configure this plugin. Create a new Hudson job and on the project configuration screen under Build, notice that the Add Build Step menu has an option "Say hello". Adding this build step will invoke the custom HelloWorld Builder which prints a "Hello" message to the console output of a job build.
Under the Covers
Plugin Discovery
Hudson automagically discovered the HelloWorldBuilder class because it is annotated with @Extension and it extends Builder, which is a defined Hudson extenson point. Other defined extensions points can be found here: http://wiki.hudson-ci.org/display/HUDSON/Extension+points
Jelly
After discovering the HelloWorldBuilder, Hudson found the UI resources for this plugin using the package and classname. Hudson uses Jelly for generating HTML.
The plugin ships with 2 jelly files, global.jelly and config.jelly. As the name implies, global.jelly provides the UI elements that are displayed on the global Hudson configuration screen. config.jelly provides the UI elements that are displayed in the job configuration screen.
Explaining jelly is beyond the scope of this document. I found jelly easy enough to learn by example using other Hudson plugins for reference.
Stapler
Hudson uses the Stapler to associate jelly files with plugins. In MVC terms, your plugin class is the "M", Jelly is the "V", Stapler is the "C". To associate Jelly files with a plugin class using Stapler, you create a resource directory under src/main/resources/{package}/{Class}/ and drop the jelly files in there. For example, if the fully-qualified name of your plugin is demo.hudson.HelloWorldBuilder then your jelly files must be located under src/main/resources/demo/hudson/HelloWorldBuilder. If you ever rename or repackage your plugin class, you must also reorganize your resource subdirectories appropriately.
Stapler is used for more than just stapling jelly files to plugins. It's also used to dispatch requests to the plugin classes. Once again, Stapler does this all by convention. If you have a form that submits to /foo/bar/SomePlugin then Stapler will try to invoke the doSubmit method on foo.bar.SomePlugin. Likewise, if a form field needs to be validated, then Stapler will call the method SomePlugin.checkSomeField. I found this to be the most confusing part of plugin development. It's fairly straightforward until it doesn't work, then it's a lot of spellchecking and consulting the Stapler docs to try to figure out what you're doing wrong.
Configuration Persistance
After configuring the plugin, you may be wondering how it gets stored or why it's not being stored. When you fire up the plugin via hpi:run, you'll see a work directory created under the project directly. This directory contains all plugin and job configuration as well as job run history logs. Global plugin configuration is stored under work/{plugin-name}.xml. Per job plugin configuration is stored under work/jobs/{jobname}/{plugin-name}.xml.
More information on configuration persistance can be found here: http://wiki.hudson-ci.org/display/HUDSON/Architecture
Going Beyond HelloWorldBuilder
Once you've mastered the HelloWorldBuilder plugin, you're ready to invent your plugin. The first place to start is by find the right extension point(s) to hook into. The complete list of extension points can be found here: http://wiki.hudson-ci.org/display/HUDSON/Extension+points
Most plugins seem to extend Builder, BuildWrapper and Action. Hopefully by now I've provided you enough information to dissect how an existing plugin works. I found that looking at existing plugins gave me nearly enough insight to accomplish what I wanted. There are a wealth of plugins on Hudson with full-source code. Start here to find a plugin that looks similar to what you are trying to accomplish. Then download the project source from https://hudson.dev.java.net/svn/hudson/trunk/hudson/plugins/ (login credentials are user=guest with empty password).
Overall, I found writing a Hudson plugin fairly easy once I understood the architecture. There isn't a lot of reference material out there beyond the Hudson tutorial. The Javadoc is generally better than most open source projects I've encountered. I definitely had some frustrating moments, especially when working with Stapler. There's a fairly good community of Hudson developers with ample source code to refer to when you get stuck.
Tuesday, July 6, 2010
Trends in Java
This week I'll be attending No Fluff Just Stuff: Salt Lake City edition. I last attended NFJS 3 years ago. Looking at the list of sessions and topics this year compared to 3 years ago has me thinking about trends in Java.
I'm glad to see there are a number of presentations on core Java. 3 years ago I was surprised that a Java conference featured so few topics about Java. Most surprising was a keynote by Neal Ford where he essentially claimed Java was dead (or at least dying). I don't remember all his arguments, but there were a few interesting that I'll paraphrase. He said that Java was nearly 15 years old which is typically the lifetime of a language; Java has too much ceremony and is too verbose; Java has become too complicated; the legacy of Java is the JVM and its future will be alternative languages on the JVM. I'd agree with the latter point the most.
Java is not dead no matter how hard Neal Ford wishes it was. If Java is dead, then there is a lot of software necrophilia going on. It's still the number 1 language being used for application development. At Overstock, we are heavy into Java and we are still getting a lot of mileage out of it. Senior Java developers are under extremely high demand in the Salt Lake City area.
Alternative languages on the JVM are still gaining momentum though. NFJS this year features a number of sessions on Groovy and Scala. Newcomer Clojure has a small mention. Gone from 3 years ago is JRuby. No mention of Jython either. Can we call JRuby and Jython dead? I hardly hear them talked about anymore.
Despite the strength of Groovy and Scala, I don't think they will kill Java. My prediction is that Java will commit suicide though we're likely years away from that. My guess is that at some point Oracle will realize that evolving Java is too difficult and costly and declare it end of life. The release of Java 7 has convinced me of this. Consider the timeline of previous Java releases:
1.0 (January 23, 1996)
1.1 (February 19, 1997)
1.2 (December 8, 1998)
1.3 (May 8, 2000)
1.4 (February 6, 2002)
5.0 (September 30, 2004)
6.0 (December 11, 2006)
7.0 2011???
Trends like this are hard to correct. It's a vicious cycle when big projects are continually delayed. Morale goes down, short cuts are taken and developers abandon ship. It takes drastic changes to reverse the cycle and so far it doesn't appear that has happened, though Oracle may be playing this one close to the chest. It's good to see Oracle has at least put some developers on the closures feature that was announced last year.
Despite the dreary state of Java 7, the Java community is still going strong. There are still libraries emerging that demonstrate some powerful features in the JDK that have yet to be tapped to their potential. You don't hear much about Java Instrumentation but take a look at what JMockit has done with it and you'll be pretty amazed. Likewise, you don't hear much about Annotation Processing Tool but Project Lombok has done some interesting (and slightly scary) things.
For now, I'll be attending the core Java sessions at NFJS. It's what I use today and what I expect to be using for the forseeable future. I may attend a Scala session because I've been fooling on and off with Scala, mostly because its interesting. Overall, I'm pretty excited about the sessions.
I'm glad to see there are a number of presentations on core Java. 3 years ago I was surprised that a Java conference featured so few topics about Java. Most surprising was a keynote by Neal Ford where he essentially claimed Java was dead (or at least dying). I don't remember all his arguments, but there were a few interesting that I'll paraphrase. He said that Java was nearly 15 years old which is typically the lifetime of a language; Java has too much ceremony and is too verbose; Java has become too complicated; the legacy of Java is the JVM and its future will be alternative languages on the JVM. I'd agree with the latter point the most.
Java is not dead no matter how hard Neal Ford wishes it was. If Java is dead, then there is a lot of software necrophilia going on. It's still the number 1 language being used for application development. At Overstock, we are heavy into Java and we are still getting a lot of mileage out of it. Senior Java developers are under extremely high demand in the Salt Lake City area.
Alternative languages on the JVM are still gaining momentum though. NFJS this year features a number of sessions on Groovy and Scala. Newcomer Clojure has a small mention. Gone from 3 years ago is JRuby. No mention of Jython either. Can we call JRuby and Jython dead? I hardly hear them talked about anymore.
Despite the strength of Groovy and Scala, I don't think they will kill Java. My prediction is that Java will commit suicide though we're likely years away from that. My guess is that at some point Oracle will realize that evolving Java is too difficult and costly and declare it end of life. The release of Java 7 has convinced me of this. Consider the timeline of previous Java releases:
1.0 (January 23, 1996)
1.1 (February 19, 1997)
1.2 (December 8, 1998)
1.3 (May 8, 2000)
1.4 (February 6, 2002)
5.0 (September 30, 2004)
6.0 (December 11, 2006)
7.0 2011???
Trends like this are hard to correct. It's a vicious cycle when big projects are continually delayed. Morale goes down, short cuts are taken and developers abandon ship. It takes drastic changes to reverse the cycle and so far it doesn't appear that has happened, though Oracle may be playing this one close to the chest. It's good to see Oracle has at least put some developers on the closures feature that was announced last year.
Despite the dreary state of Java 7, the Java community is still going strong. There are still libraries emerging that demonstrate some powerful features in the JDK that have yet to be tapped to their potential. You don't hear much about Java Instrumentation but take a look at what JMockit has done with it and you'll be pretty amazed. Likewise, you don't hear much about Annotation Processing Tool but Project Lombok has done some interesting (and slightly scary) things.
For now, I'll be attending the core Java sessions at NFJS. It's what I use today and what I expect to be using for the forseeable future. I may attend a Scala session because I've been fooling on and off with Scala, mostly because its interesting. Overall, I'm pretty excited about the sessions.
Saturday, July 3, 2010
Interesting change to method signature erasure rules in Java 7
I found an interesting "bug" that has been fixed in Java 7 compiler. I say "bug" because some may have considered the old behavior to be a nice feature.
Consider the following class:
public class ListPrinter {
public static String getExample(List<String> list) {
return list.get(0); // return first
}
public static Integer getExample(List<Integer> list) {
return list.get(list.size() - 1); // return last
}
public static void main(String[] args) {
System.out.println(getExample(Arrays.asList("1", "2", "3")));
System.out.println(getExample(Arrays.asList(1, 2, 3)));
}
}
In Java 5 and 6, this compiles fine. We have 2 overloaded methods to get an example element from a list. For Lists of String, the first element is returned. For Lists of Integer, the last element is returned. Running the code prints the expected output:
1
3
Obviously, the compiler did the right thing, so what's the problem? Let's look at what happens after type erasure. Running javap on the above class compiled with JDK 6, yields:
public class ListPrinter extends java.lang.Object{
public ListPrinter();
public static java.lang.String getExample(java.util.List);
public static java.lang.Integer getExample(java.util.List);
public static void main(java.lang.String[]);
}
That's interesting, we've got 2 methods with the same signature getExample(java.util.List) but different return types. The discussion section for 8.4.8.3 of the Java language spec states that "...methods declared in the same class with the same name must have different erasures." The first part is completely clear, but the last part requires some thought. Does different erasure mean:
A) different arguments after erasure
B) different arguments and return type after erasure
In Java 7, the answer is A. But in Java 5 and 6, the answer was B. By strict interpretation, Java 7 got it right. Method overloading requires changing the number and/or types of method arguments. Method signatures are not allowed to differ only by return type. As proof, let's perform the type erasure on the source code:
import java.util.List;
import java.util.ArrayList;
import java.util.Arrays;
public class ListPrinter {
public static String getExample(List list) {
return (String) list.get(0); // return first
}
public static Integer getExample(List list) {
return (Integer) list.get(list.size() - 1); // return last
}
public static void main(String[] args) {
System.out.println(getExample(Arrays.asList("1", "2", "3")));
System.out.println(getExample(Arrays.asList(1, 2, 3)));
}
}
Compiling this version of the code in JDK 6 generates the following error: ListPrinter.java:11: getExample(java.util.List) is already defined in ListPrinterThe compiler is telling us that we cannot have more one than method with the signature getExample(java.util.List). Notice that this is the exact signature that JDK 6 compiler generated twice in the original example. The compiler let us cheat. In Java 7, the original example fails to compile with the error:
ListPrinter.java:11: name clash: getExample(ListThank goodness Java finally fixed that bug. But wait...it was kind of cool that JDK 6 let us do that. Is this a bug or a feature? The compiler figured it out and did the right thing so again I ask, "what's the problem"? The problem is erasure. And it's a problem that Java will likely always be stuck with. I guess it's time to start using Scala. But wait, Scala has type erasure too. Now, here's the million dollar question. What does Scala do in this situation? Here's the equivalient code written in Scala:) and getExample(List ) have the same erasure
object ListPrinter extends Application {
def getExample(list: List[String]):String = list.head
def getExample(list: List[Int]):Int = list.last
override def main(args: Array[String])
{
println(getExample(List("1", "2", "3")))
println(getExample(List(1, 2, 3)))
}
}
Scala inherits the same rules for overloading with type erasure from Java. But which interpretation of this rule does it use? As an incentive to get people to try Scala, I'm going to let the reader answer this question for themselves by compiling the code. The result may surprise you.
Friday, May 14, 2010
Java CPU Usage Profiling
Recently I was working on a Java application that was pegging my CPU. Since this application was multi-threaded, I started looking for simple ways to determine which part of the application was the culprit. Since JConsole and VisualVM come bundled with Java 6 SDK I started looking at what they had to offer.
First we'll look at JConsole. Out of the box, JConsole provides a Threads tab that allows you to view what threads are running and generate a stack trace for a thread. It's essentially thread dumps with a GUI. It's not so useful for determining which threads are most active.
After a little more digging and I found a JConsole plugin called topthreads which is an enhanced version of the JTop plugin that ships with the JDK. For an overview of running topthreads, go here. You'll need to download the jar mentioned toward the bottom of the article and then fire up JConsole with the plugin:
The top threads plugin gives a much better view of the threads that are consuming the most CPU time:
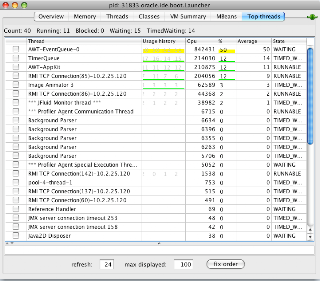
Once you find a suspicious thread, you can switch back to the Threads tab in JConsole and get a stack trace of the thread. To really see what the thread is doing you'll likely need to take multiple snapshots of the thread and see what progress, if any, the thread is making.
Topthreads may help you find a rogue thread in a multithread application but it is not much help if you have a single threaded application that is performing poorly. Or perhaps you have a multithread application where several similar threads are taking up a large amount of cpu.
In my own debugging, I found that it wasn't the threads I cared about so much as the methods. Ultimately, you want to know which methods are taking up the most processing time. Enter VisualVM.
VisualVM contains a pretty impressive profiling tool that's easy to use. To get started with profiling with VisualVM, go here.
The profiler in VisualVM gives a nice view of top methods which can be sorted by time and invocations:
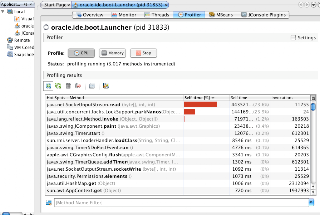
One downside to VisualVM's profiling is that it tanks the CPU when you first start profiling. The application your profiling will be limping for about 10 seconds while VisualVM digs in its profiling. It also adds a small bit of drag after profiling begins. By contrast, topthreads didn't add any noticable drag or hit on startup. Despite the performance penalty, I found VisualVM much better for profiling application performance.
First we'll look at JConsole. Out of the box, JConsole provides a Threads tab that allows you to view what threads are running and generate a stack trace for a thread. It's essentially thread dumps with a GUI. It's not so useful for determining which threads are most active.
After a little more digging and I found a JConsole plugin called topthreads which is an enhanced version of the JTop plugin that ships with the JDK. For an overview of running topthreads, go here. You'll need to download the jar mentioned toward the bottom of the article and then fire up JConsole with the plugin:
jconsole -pluginpath /path/to/topthreads.jar
The top threads plugin gives a much better view of the threads that are consuming the most CPU time:

Once you find a suspicious thread, you can switch back to the Threads tab in JConsole and get a stack trace of the thread. To really see what the thread is doing you'll likely need to take multiple snapshots of the thread and see what progress, if any, the thread is making.
Topthreads may help you find a rogue thread in a multithread application but it is not much help if you have a single threaded application that is performing poorly. Or perhaps you have a multithread application where several similar threads are taking up a large amount of cpu.
In my own debugging, I found that it wasn't the threads I cared about so much as the methods. Ultimately, you want to know which methods are taking up the most processing time. Enter VisualVM.
VisualVM contains a pretty impressive profiling tool that's easy to use. To get started with profiling with VisualVM, go here.
The profiler in VisualVM gives a nice view of top methods which can be sorted by time and invocations:

One downside to VisualVM's profiling is that it tanks the CPU when you first start profiling. The application your profiling will be limping for about 10 seconds while VisualVM digs in its profiling. It also adds a small bit of drag after profiling begins. By contrast, topthreads didn't add any noticable drag or hit on startup. Despite the performance penalty, I found VisualVM much better for profiling application performance.
Wednesday, March 31, 2010
Hibernate and last modified date
A common practice is to put insert date and last modified date columns in a table. Hibernate/JPA provides a Version annotation which works nicely for managing the last modified date column. Managing create date is easily accomplished by initializing create date via the constructor.
Example:
In addition to autopopulating the "lastModified" property, @Version will enable optimistic locking. Anytime the AuditEntity is updated in the database, Hibernate will add an additional statement to the "where" clause of the update statement such as
If another update has been committed in another session since the time the record was loaded in your session, the update on your session will throw a StaleObjectStateException. I don't have much experience with optmisitic locking in Hibernate, but that seems like a very slick way of detecting and preventing race conditions in systems where multiple users or processes could be updating the same record.
For those who want Hibernate to manage the last modified date column but don't want optimistic locking, another alternative is to use an event listener to set the lastModified property. I happened upon this solution before discovering the versioning solution. For this use case, I would use the versioning solution because its simple and I like optimistic locking. However the event listener solution can be customized to handle more complex use cases.
Here is a basic recipe for using event listeners to set the last modified date.
1. Create an interface called LastModifiable:
2. Create a Listener that listens for the SaveOrUpdateEvent on Dateable entities and modifies the create and/or update properties:
3. Configure the above listener via hibernate.cfg.xml:
Once these pieces are in place, any entity that implements the LastModifiable interface will automatically have its lastModified properties managed by hibernate.
Here is an example entity:
Example:
import java.util.Date;
@Entity
@Table(name="audit_example")
public class AuditEntity {
@Id private long id;
private Date created;
@Version private Date lastModified;
public AuditEntity() {
created = new Date();
}
public long getId() { return id; }
public Date getCreated() { return created; }
public Date getLastModified() { return lastModified; }
public void setCreated(Date created) { this.created = created; }
public void setLastModified(Date date) { this.lastModified = date; }
}
In addition to autopopulating the "lastModified" property, @Version will enable optimistic locking. Anytime the AuditEntity is updated in the database, Hibernate will add an additional statement to the "where" clause of the update statement such as
update audity_entity
set ...
where id=:id and lastModified=:oldTimestamp
If another update has been committed in another session since the time the record was loaded in your session, the update on your session will throw a StaleObjectStateException. I don't have much experience with optmisitic locking in Hibernate, but that seems like a very slick way of detecting and preventing race conditions in systems where multiple users or processes could be updating the same record.
For those who want Hibernate to manage the last modified date column but don't want optimistic locking, another alternative is to use an event listener to set the lastModified property. I happened upon this solution before discovering the versioning solution. For this use case, I would use the versioning solution because its simple and I like optimistic locking. However the event listener solution can be customized to handle more complex use cases.
Here is a basic recipe for using event listeners to set the last modified date.
1. Create an interface called LastModifiable:
import java.util.Date;
public interface LastModifiable {
public void setLastModified(Date date);
}
2. Create a Listener that listens for the SaveOrUpdateEvent on Dateable entities and modifies the create and/or update properties:
import org.hibernate.event.SaveOrUpdateEvent;
import org.hibernate.event.def.DefaultSaveOrUpdateEventListener;
public class SaveOrUpdateDateListener extends DefaultSaveOrUpdateEventListener {
@Override
public void onSaveOrUpdate(SaveOrUpdateEvent event) {
if (event.getObject() instanceof LastModifiable) {
LastModifiable record = (LastModifiable) event.getObject();
audit.setLastModified(new Date());
}
super.onSaveOrUpdate(event);
}
}
3. Configure the above listener via hibernate.cfg.xml:
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
.....
<event type="save-update">
<listener class="SaveOrUpdateDateListener"/>
</event>
</session-factory>
</hibernate-configuration>
Once these pieces are in place, any entity that implements the LastModifiable interface will automatically have its lastModified properties managed by hibernate.
Here is an example entity:
@Entity
@Table(name="audit_example")
public class AuditEntity implements LastModifiable {
@Id private long id;
private Date created;
private Date lastModified;
public AuditEntity() {
created = new Date();
}
public AuditEntity(long id) { this.id = id; }
public long getId() { return id; }
public Date getCreated() { return created; }
public Date getLastModified() { return updated; }
public void setCreated(Date date) { this.created = date; }
public void setLastModified(Date date) { this.lastModified = date; }
}
Monday, March 1, 2010
Git or Mercurial as a replacement for SVN
Are DVCS tools like Git and Mercurial better alternatives than SVN for a company using a central repository? Does DVCS makes sense for a company where all development is done from the same location? These were the main questions I had on my mind as I investigated alternatives to SVN at Overstock.com.
The short answer is that, yes, Git and Mercurial can function as a central repository. And yes, there are benefits to using DVCS even if the IT department is centrally located. But there are costs as well. The long answer is, well, long and that's what I'll try to address in this post.
Before I go into the tools, let me give you a little background about Overstock.com. We have a few public facing applications (e.g. www.overstock.com) and many dozen internal applications. Our applications are mostly Java. Our projects are organized as multi-module Maven projects. We use Hudson for builds and Nexus for a Maven repostiry. We have a handful of SVN repos each containing a couple dozen projects. Most developers use Eclipse though a few use IntelliJ. Developers are organized into teams of 4-6, and all work from the same office. Each teams works on a handful of projects.
Our development staff has been growing rapidly. 4 years ago we had less than 25 developers but now we have over 100 developers. When we had a small number of developers, we generally put features on branches and merged them into trunk periodically. Since there weren't that many branches, there weren't that many surprises at merge time. But this doesn't scale well. 100 developers with lots of branches makes for some painful merging with SVN. SVN is pretty lousing at merging. If you move a file on a branch (think refactoring), and that file has been modified on trunk, you will have problems when you merge that branch into trunk. And SVN forces you to keep track of the "to" and "from" revisions which is error prone. SVN 1.5 was supposed to have better merging capabilities but from what I've seen, it's still broken.
OK, so we all agree SVN the tool is pretty lousy for large scale development. But what about a central repository? For Overstock.com, a central repository makes a lot of sense. It is automatically backed up and highly available. Everyone knows where to find the latest version of the code. Everyone has visibility into what other people are working on.
It would seem the perfect solution for Overstock is a next-generation VCS tool with a central repository. Everyone seems to agree that the next-generation tools are all better than SVN. Of the next-generation VCS, Git and Mercurial have the best industry support and momentum at the moment. Git has the Linux community. Mercurial has some big names supporting it too like Google.
We could just choose Git based on all the buzz but we don't change VCS often so its worth investigating Mercurial too. Looking at a feature comparision, they seem pretty similar. Google code seems to think that Mercurial is more efficient but Git is more powerful and complicated.
From my investigation I found that both tools offer vastly superior command-line features to SVN and both are very similar in both features and performance. Their philosophies are very different though. One blog used the analogy that Git is McGyver and Mercurial is James Bond. I would spin that a bit and say that McGyver would use Git and James Bond would use Mercurial.
At first glance, Git has more features. This is because Git enables just about everything by default. Git also feels more geeky in its syntax. It took me longer to get used to.
Mercurial takes a different approach. Instead of enabling everything, you enable only what you need. By default, only the commonly used features, known as extensions, are enabled. Extensions like hgk (analogous to Git's gitk) are packaged with Mercurial but need to be enabled. Some extensions also need to be downloaded before they can be enabled. Enabling extensions is pretty painless from what I found. I also found the defaults more sensible for cloning, branching, merging and reverting.
I suspect that if you enabled all the features of Git and Mercurial, you'd end up with nearly identical feature sets. Both tools are still growing so any features lacking in one of the the other will likely be added within a few weeks or months.
By far the most compelling features of Git and Mercurial for me are the merge capabilities. In this area, neither tool disappointed. I created many branches, moved files in one branch and modified them in another. Merging them together was simple and worked correctly. I didn't have to do all that revision bookkeeping like I have to with subversion. Both Git and Mercurial merged changes across moved files beautifully. At last, merging that works like its supposed to.
Now for some bad news. Perhaps you caught on to my wording above where I said Git and Mercurial have better command-line features than SVN. When it comes to Eclipse plugins, SVN is better than Mercurial and vastly better than Git. For most developers at Overstock, the majority of their interaction with the code repository is via Eclipse. Perhaps this is because the Eclipse plugins (subversive and subclipse) have spoiled us. I think it's important to understand how to use SVN from the command-line, and sometimes it's actually easier. But there are some functions that just make more sense in the IDE. Generally these are tasks which involve looking at multiple files or revisions such as synchronize with repository, browse repository, show annotations, merge and show history.
At the time of review, the Git Eclipse plugin is very unstable and missing many of the features. This is likely because the Git plugin developers have their hands full with reimplementing Git in Java. At the moment, you cannot synchronize with repository or browse repositories. I was also unable to merge if there were conflicts. As soon as a conflict was encountered it just aborted. For those using multi-module Maven projects with the M2E plugin, you're out of luck. The Git plugin cannot be enabled for these projects. I also found that the plugin crashed Eclipse nearly every session.
Mercurial has at least a decent Eclipse plugin. There are at least 2 that I found and I can definitely recommend HgEclipse. It has most the features of the SVN plugins. It works with multi-module maven and M2E. It annoyingly asks for my password multiple times when pushing or pulling to a remote repo. It was so annoying I had to set up passwordless ssh to the remote repo. But it was stable and usable.
Eclipse plugins aside, the next issue I encountered with both Git and Mercurial was dealing with our SVN repos that contain a lots of projects. With SVN, we only have a few repos. One repo is for internal applications, another for the website and related services, and so on. Generally, when you are working on a feature you only check out a small subset of projects from a repo. This doesn't map well to Git or Mercurial. Neither tools supports partial clones/checkouts. You have to check out the whole repo even if you just want to modify one file. There are 3 alternatives for migrating. 1) Convert every project to a repo. 2) Keep the same structure. Option 3) Use an extension to roll your own repo of repos.
Option 1 means that our 5-10 repos become several dozen repos. Now we'll need a tool for hosting all these repos. There are a few public tools like GitHub or Googlecode, but not so many options for private hosting.
Option 2 means cloning an entire repo just to work on one of its projects. This might not be so bad for smaller repos but it does not scale.
Option 3 involves using an extension like NestedRepositories for Mercurial or Submodules for Git. Git's submodules are not well-suited for making a repo of repos. It felt akin to hard links in unix and it's not really intended for this purpose. Mercurial's NestedRepositories look more promising but I have not had time to play with them. It mentions the following relevant use case: "Partial views: a developer who only needs to work with two out of twelve modules should not have to download or deal with the other ten."
Now the choice does not seem so obvious. If I had to choose between Mercurial and Git at Overstock right now, I'd pick Mercurial, with emphasis on right now. As I said before, both tools are still expanding and evolving so I could easily see Git becoming a better choice in 6 months to a year. At the moment, neither tools is compelling enough for me to recommend abandoning svn. For our situation, my recommendation is to just wait and see. From a personal interest, I'd really like to use Git or Mercurial, but it just doesn't make sense right now for the company. Hopefully in the next year or two the tools will evolve in such a way that it does it make sense. Or our needs will evolve in such a way that SVN no longer makes any sense.
The short answer is that, yes, Git and Mercurial can function as a central repository. And yes, there are benefits to using DVCS even if the IT department is centrally located. But there are costs as well. The long answer is, well, long and that's what I'll try to address in this post.
Before I go into the tools, let me give you a little background about Overstock.com. We have a few public facing applications (e.g. www.overstock.com) and many dozen internal applications. Our applications are mostly Java. Our projects are organized as multi-module Maven projects. We use Hudson for builds and Nexus for a Maven repostiry. We have a handful of SVN repos each containing a couple dozen projects. Most developers use Eclipse though a few use IntelliJ. Developers are organized into teams of 4-6, and all work from the same office. Each teams works on a handful of projects.
Our development staff has been growing rapidly. 4 years ago we had less than 25 developers but now we have over 100 developers. When we had a small number of developers, we generally put features on branches and merged them into trunk periodically. Since there weren't that many branches, there weren't that many surprises at merge time. But this doesn't scale well. 100 developers with lots of branches makes for some painful merging with SVN. SVN is pretty lousing at merging. If you move a file on a branch (think refactoring), and that file has been modified on trunk, you will have problems when you merge that branch into trunk. And SVN forces you to keep track of the "to" and "from" revisions which is error prone. SVN 1.5 was supposed to have better merging capabilities but from what I've seen, it's still broken.
OK, so we all agree SVN the tool is pretty lousy for large scale development. But what about a central repository? For Overstock.com, a central repository makes a lot of sense. It is automatically backed up and highly available. Everyone knows where to find the latest version of the code. Everyone has visibility into what other people are working on.
It would seem the perfect solution for Overstock is a next-generation VCS tool with a central repository. Everyone seems to agree that the next-generation tools are all better than SVN. Of the next-generation VCS, Git and Mercurial have the best industry support and momentum at the moment. Git has the Linux community. Mercurial has some big names supporting it too like Google.
We could just choose Git based on all the buzz but we don't change VCS often so its worth investigating Mercurial too. Looking at a feature comparision, they seem pretty similar. Google code seems to think that Mercurial is more efficient but Git is more powerful and complicated.
From my investigation I found that both tools offer vastly superior command-line features to SVN and both are very similar in both features and performance. Their philosophies are very different though. One blog used the analogy that Git is McGyver and Mercurial is James Bond. I would spin that a bit and say that McGyver would use Git and James Bond would use Mercurial.
At first glance, Git has more features. This is because Git enables just about everything by default. Git also feels more geeky in its syntax. It took me longer to get used to.
Mercurial takes a different approach. Instead of enabling everything, you enable only what you need. By default, only the commonly used features, known as extensions, are enabled. Extensions like hgk (analogous to Git's gitk) are packaged with Mercurial but need to be enabled. Some extensions also need to be downloaded before they can be enabled. Enabling extensions is pretty painless from what I found. I also found the defaults more sensible for cloning, branching, merging and reverting.
I suspect that if you enabled all the features of Git and Mercurial, you'd end up with nearly identical feature sets. Both tools are still growing so any features lacking in one of the the other will likely be added within a few weeks or months.
By far the most compelling features of Git and Mercurial for me are the merge capabilities. In this area, neither tool disappointed. I created many branches, moved files in one branch and modified them in another. Merging them together was simple and worked correctly. I didn't have to do all that revision bookkeeping like I have to with subversion. Both Git and Mercurial merged changes across moved files beautifully. At last, merging that works like its supposed to.
Now for some bad news. Perhaps you caught on to my wording above where I said Git and Mercurial have better command-line features than SVN. When it comes to Eclipse plugins, SVN is better than Mercurial and vastly better than Git. For most developers at Overstock, the majority of their interaction with the code repository is via Eclipse. Perhaps this is because the Eclipse plugins (subversive and subclipse) have spoiled us. I think it's important to understand how to use SVN from the command-line, and sometimes it's actually easier. But there are some functions that just make more sense in the IDE. Generally these are tasks which involve looking at multiple files or revisions such as synchronize with repository, browse repository, show annotations, merge and show history.
At the time of review, the Git Eclipse plugin is very unstable and missing many of the features. This is likely because the Git plugin developers have their hands full with reimplementing Git in Java. At the moment, you cannot synchronize with repository or browse repositories. I was also unable to merge if there were conflicts. As soon as a conflict was encountered it just aborted. For those using multi-module Maven projects with the M2E plugin, you're out of luck. The Git plugin cannot be enabled for these projects. I also found that the plugin crashed Eclipse nearly every session.
Mercurial has at least a decent Eclipse plugin. There are at least 2 that I found and I can definitely recommend HgEclipse. It has most the features of the SVN plugins. It works with multi-module maven and M2E. It annoyingly asks for my password multiple times when pushing or pulling to a remote repo. It was so annoying I had to set up passwordless ssh to the remote repo. But it was stable and usable.
Eclipse plugins aside, the next issue I encountered with both Git and Mercurial was dealing with our SVN repos that contain a lots of projects. With SVN, we only have a few repos. One repo is for internal applications, another for the website and related services, and so on. Generally, when you are working on a feature you only check out a small subset of projects from a repo. This doesn't map well to Git or Mercurial. Neither tools supports partial clones/checkouts. You have to check out the whole repo even if you just want to modify one file. There are 3 alternatives for migrating. 1) Convert every project to a repo. 2) Keep the same structure. Option 3) Use an extension to roll your own repo of repos.
Option 1 means that our 5-10 repos become several dozen repos. Now we'll need a tool for hosting all these repos. There are a few public tools like GitHub or Googlecode, but not so many options for private hosting.
Option 2 means cloning an entire repo just to work on one of its projects. This might not be so bad for smaller repos but it does not scale.
Option 3 involves using an extension like NestedRepositories for Mercurial or Submodules for Git. Git's submodules are not well-suited for making a repo of repos. It felt akin to hard links in unix and it's not really intended for this purpose. Mercurial's NestedRepositories look more promising but I have not had time to play with them. It mentions the following relevant use case: "Partial views: a developer who only needs to work with two out of twelve modules should not have to download or deal with the other ten."
Now the choice does not seem so obvious. If I had to choose between Mercurial and Git at Overstock right now, I'd pick Mercurial, with emphasis on right now. As I said before, both tools are still expanding and evolving so I could easily see Git becoming a better choice in 6 months to a year. At the moment, neither tools is compelling enough for me to recommend abandoning svn. For our situation, my recommendation is to just wait and see. From a personal interest, I'd really like to use Git or Mercurial, but it just doesn't make sense right now for the company. Hopefully in the next year or two the tools will evolve in such a way that it does it make sense. Or our needs will evolve in such a way that SVN no longer makes any sense.
Subscribe to:
Posts (Atom)